Concatenated organization
This is an abridged version of the introduction to Vinum on the LEMIS web site. See that site for more details.
Many BSD systems have storage needs which current generation disks can't fulfill by themselves: they may want more storage, more performance or more reliability than an individual disk can provide. There are several alternatives solutions to these issues, generally known by the generic term RAID (Redundant Array of Inexpensive Disks).
One solution is to use a special disk controller, called a RAID controller. This controller creates an interface to a virtual disk which shows the desired characteristics.
The problem with RAID controllers is that they are not compatible with other controllers, so special drivers are needed. Currently, only FreeBSD and NetBSD support any RAID controllers, and in each case only the DPT SmartRAID and SmartCache III and IV are supported. These are old models which are no longer in production. Drivers for newer controllers from DPT, Mylex and AMD are on their way, though.
An alternative is a ``SCSI-SCSI'' RAID controller. This kind of controller doesn't interface to the system directly, it interfaces to the SCSI bus. This means it doesn't need a special driver, but it also limits performance somewhat.
Let's look again at the problems we're trying to solve:
Vinum solves this problem with virtual disks, which it calls volumes, a term borrowed from VERITAS. These disks have essentially the same properties as a UNIX disk drive, though there are some minor differences. Volumes have no size limitations.
Current disk drives can transfer data sequentially at up to 30 MB/s, but this value is of little importance in an environment where many independent processes access a drive, where they may achieve only a fraction of these values. In such cases it's more interesting to view the problem from the viewpoint of the disk subsystem: the important parameter is the load that a transfer places on the subsystem, in other words the time for which a transfer occupies the drives involved in the transfer.
In any disk transfer, the drive must first position the heads, wait for the first sector to pass under the read head, and then perform the transfer. These actions can be considered to be atomic: it doesn't make any sense to interrupt them.
Consider a typical transfer of about 10 kB: the current generation of high-performance disks can position the heads in an average of 6 ms. The fastest drives spin at 10,000 rpm, so the average rotational latency (half a revolution) is 3 ms. At 30 MB/s, the transfer itself takes about 350 µs, almost nothing compared to the positioning time. In such a case, the effective transfer rate drops to a little over 1 MB/s and is clearly highly dependent on the transfer size.
The traditional and obvious solution to this bottleneck is ``more spindles'': rather than using one large disk, it uses several smaller disks with the same aggregate storage space. Each disk is capable of positioning and transferring independently, so the effective throughput increases by a factor close to the number of disks used.
The exact throughput improvement is, of course, smaller than the number of disks involved: although each drive is capable of transferring in parallel, there is no way to ensure that the requests are evenly distributed across the drives. Inevitably the load on one drive will be higher than on another.
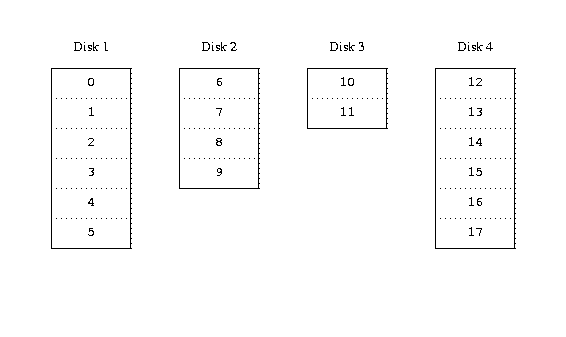
The evenness of the load on the disks is strongly dependent on the way the data is shared across the drives. In the following discussion, it's convenient to think of the disk storage as a large number of data sectors which are addressable by number, rather like the pages in a book. The most obvious method is to divide the virtual disk into groups of consecutive sectors the size of the individual physical disks and store them in this manner, rather like taking a large book and tearing it into smaller sections. This method is called concatenation and has the advantage that the disks do not need to have any specific size relationships. It works well when the access to the virtual disk is spread evenly about its address space. When access is concentrated on a smaller area, the improvement is less marked. The following figure illustrates the sequence in which storage units are allocated in a concatenated organization.
Concatenated organization
An alternative mapping is to divide the address space into smaller, even-sized components and store them sequentially on different devices. For example, the first 256 sectors may be stored on the first disk, the next 256 sectors on the next disk and so on. After filling the last disk, the process repeats until the disks are full. This mapping is called striping or RAID-0, though the latter term is somewhat misleading: it provides no redundancy. Striping requires somewhat more effort to locate the data, and it can cause additional I/O load where a transfer is spread over multiple disks, but it can also provide a more constant load across the disks. The following figure illustrates the sequence in which storage units are allocated in a striped organization.
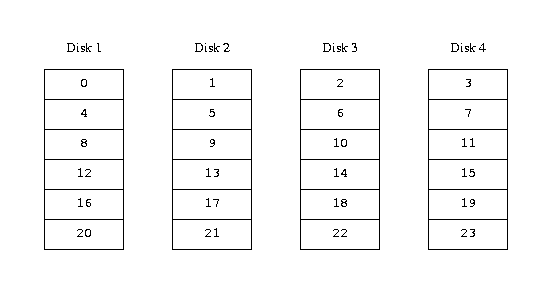
Striped organization
Vinum implements both concatenation and striping. Since it exists within the UNIX disk storage framework, it would be possible to use UNIX partitions as the building block for multi-disk plexes, but in fact this turns out to be too inflexible: UNIX disks can have only a limited number of partitions. Instead, Vinum subdivides a single UNIX partition into contiguous areas called subdisks, which it uses as building blocks for plexes.
The traditional way to approach this problem has been mirroring, keeping two copies of the data on different physical hardware. Since the advent of the RAID levels, this technique has also been called RAID level 1 or RAID-1. Any write to the volume writes to both locations; a read can be satisfied from either, so if one drive fails, the data is still available on the other drive.
Mirroring has two problems:
An alternative solution is parity, implemented in the RAID levels 2, 3, 4 and 5. Of these, RAID-5 is the most interesting. As implemented in Vinum, it is a variant on a striped organization which dedicates one block of each stripe to parity of the other blocks: As implemented by Vinum, a RAID-5 plex is similar to a striped plex, except that it implements RAID-5 by including a parity block in each stripe. As required by RAID-5, the location of this parity block changes from one stripe to the next. The numbers in the data blocks indicate the relative block numbers.
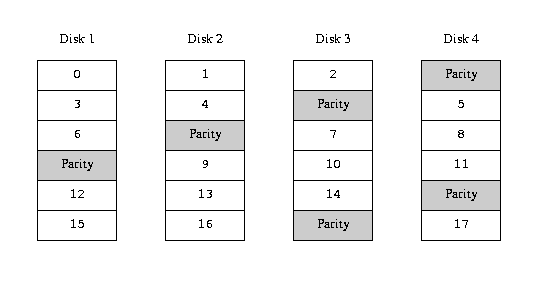
RAID-5 organization
Compared to mirroring, RAID-5 has the advantage of requiring significantly less storage space. Read access is similar to that of striped organizations, but write access is significantly slower, approximately 25% of the read performance. If one drive fails, the array can continue to operate in degraded mode: a read from one of the remaining accessible drives continues normally, but a read from the failed drive is recalculated from the corresponding block from all the remaining drives.
Vinum implements both mirroring and RAID-5. It implements mirroring by providing objects called plexes, each of which is a representation of the data in a volume. A volume may contain between one and eight plexes.
From an implementation viewpoint, it is not practical to represent a RAID-5 organization as a collection of plexes. We'll look at this issue below.
Although a plex represents the complete data of a volume, it is possible for parts of the representation to be physically missing, either by design (by not defining a subdisk for parts of the plex) or by accident (as a result of the failure of a drive).
drive a device /dev/da3h
volume myvol
plex org concat
sd length 512m drive a
This file describes a four Vinum objects:
vinum -> create config1 Configuration summary Drives: 1 Volumes: 1 Plexes: 1 Subdisks: 1 D a State: up Device /dev/da3h Avail: 2061/2573 MB (80%) V myvol State: up Plexes: 1 Size: 512 MB P myvol.p0 C State: up Subdisks: 1 Size: 512 MB S myvol.p0.s0 State: up PO: 0 B Size: 512 MBThis output shows the brief listing format of vinum(8). It is represented graphically in the following figure.
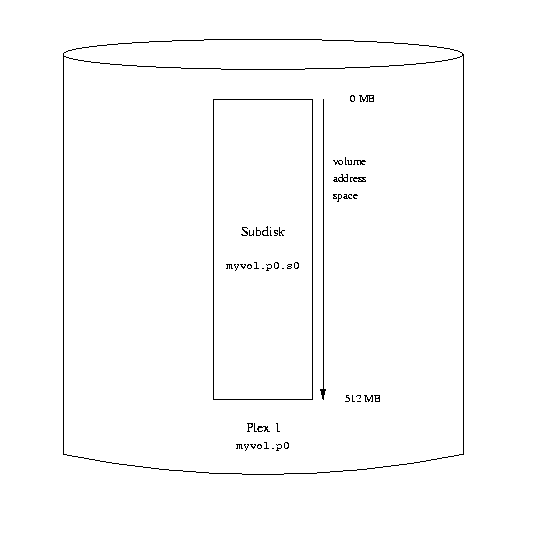
A simple Vinum volume
This figure, and the ones which follow, represent a volume, which contains the plexes, which in turn contain the subdisks. In this trivial example, the volume contains one plex, and the plex contains one subdisk.
This particular volume has no specific advantage over a conventional disk partition. It contains a single plex, so it is not redundant. The plex contains a single subdisk, so there is no difference in storage allocation from a conventional disk partition. The following sections illustrate various more interesting configuration methods.
drive b device /dev/da4h
volume mirror
plex org concat
sd length 512m drive a
plex org concat
sd length 512m drive b
In this example, it was not necessary to specify a definition of drive a
again, since Vinum keeps track of all objects in its configuration database.
After processing this definition, the configuration looks like:
Drives: 2 Volumes: 2 Plexes: 3 Subdisks: 3 D a State: up Device /dev/da3h Avail: 1549/2573 MB (60%) D b State: up Device /dev/da4h Avail: 2061/2573 MB (80%) V myvol State: up Plexes: 1 Size: 512 MB V mirror State: up Plexes: 2 Size: 512 MB P myvol.p0 C State: up Subdisks: 1 Size: 512 MB P mirror.p0 C State: up Subdisks: 1 Size: 512 MB P mirror.p1 C State: initializing Subdisks: 1 Size: 512 MB S myvol.p0.s0 State: up PO: 0 B Size: 512 MB S mirror.p0.s0 State: up PO: 0 B Size: 512 MB S mirror.p1.s0 State: empty PO: 0 B Size: 512 MBThe following figure shows the structure graphically.
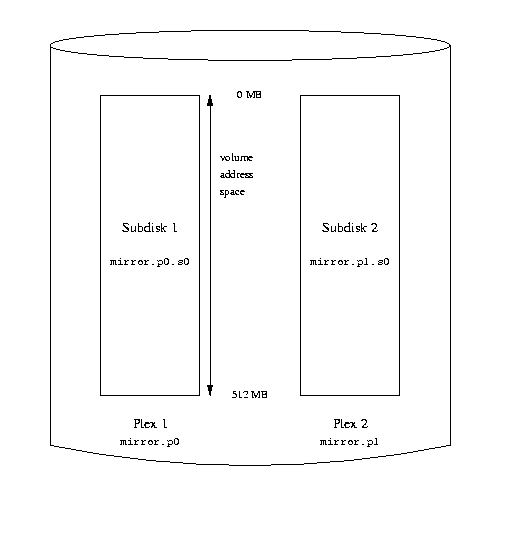
A mirrored Vinum volume
In this example, each plex contains the full 512 MB of address space. As in the previous example, each plex contains only a single subdisk.
drive c device /dev/da5h
drive d device /dev/da6h
volume stripe
plex org striped 512k
sd length 128m drive a
sd length 128m drive b
sd length 128m drive c
sd length 128m drive d
As before, it is not necessary to define the drives which are already known to Vinum. After processing this definition, the configuration looks like:
Drives: 4 Volumes: 3 Plexes: 4 Subdisks: 7 D a State: up Device /dev/da3h Avail: 1421/2573 MB (55%) D b State: up Device /dev/da4h Avail: 1933/2573 MB (75%) D c State: up Device /dev/da5h Avail: 2445/2573 MB (95%) D d State: up Device /dev/da6h Avail: 2445/2573 MB (95%) V myvol State: up Plexes: 1 Size: 512 MB V mirror State: up Plexes: 2 Size: 512 MB V striped State: up Plexes: 1 Size: 512 MB P myvol.p0 C State: up Subdisks: 1 Size: 512 MB P mirror.p0 C State: up Subdisks: 1 Size: 512 MB P mirror.p1 C State: initializing Subdisks: 1 Size: 512 MB P striped.p1 State: up Subdisks: 1 Size: 512 MB S myvol.p0.s0 State: up PO: 0 B Size: 512 MB S mirror.p0.s0 State: up PO: 0 B Size: 512 MB S mirror.p1.s0 State: empty PO: 0 B Size: 512 MB S striped.p0.s0 State: up PO: 0 B Size: 128 MB S striped.p0.s1 State: up PO: 512 kB Size: 128 MB S striped.p0.s2 State: up PO: 1024 kB Size: 128 MB S striped.p0.s3 State: up PO: 1536 kB Size: 128 MB
This volume is represented in the following figure. The darkness of the stripes indicates the position within the plex address space: the lightest stripes come first, the darkest last.
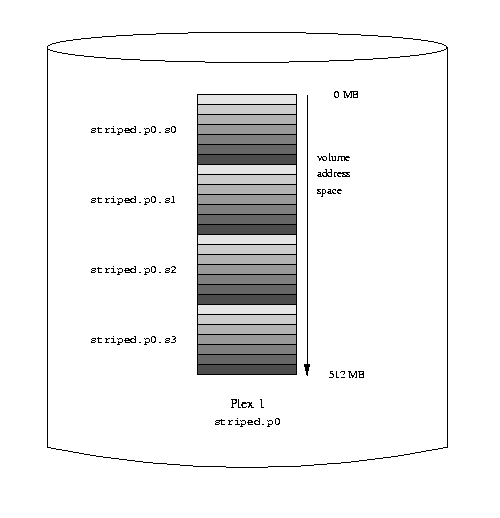
A striped Vinum volume
drive e device /dev/da6h
volume raid5
plex org raid5 512k
sd length 128m drive a
sd length 128m drive b
sd length 128m drive c
sd length 128m drive d
sd length 128m drive e
Although this plex has five subdisks, its size is the same as the plexes in the
other examples, since the equivalent of one subdisk is used to store parity
information. After processing the configuration, the system configuration is:
Drives: 5 Volumes: 4 Plexes: 5 Subdisks: 12 D a State: up Device /dev/da3h Avail: 1293/2573 MB (50%) D b State: up Device /dev/da4h Avail: 1805/2573 MB (70%) D c State: up Device /dev/da5h Avail: 2317/2573 MB (90%) D d State: up Device /dev/da6h Avail: 2317/2573 MB (90%) D e State: up Device /dev/da6h Avail: 2445/2573 MB (95%) V myvol State: up Plexes: 1 Size: 512 MB V mirror State: up Plexes: 2 Size: 512 MB V striped State: up Plexes: 1 Size: 512 MB V raid5 State: up Plexes: 1 Size: 512 MB P myvol.p0 C State: up Subdisks: 1 Size: 512 MB P mirror.p0 C State: up Subdisks: 1 Size: 512 MB P mirror.p1 C State: initializing Subdisks: 1 Size: 512 MB P striped.p0 S State: up Subdisks: 1 Size: 512 MB P raid5.p0 R State: up Subdisks: 1 Size: 512 MB S myvol.p0.s0 State: up PO: 0 B Size: 512 MB S mirror.p0.s0 State: up PO: 0 B Size: 512 MB S mirror.p1.s0 State: empty PO: 0 B Size: 512 MB S striped.p0.s0 State: up PO: 0 B Size: 128 MB S striped.p0.s1 State: up PO: 512 kB Size: 128 MB S striped.p0.s2 State: up PO: 1024 kB Size: 128 MB S striped.p0.s3 State: up PO: 1536 kB Size: 128 MB S raid5.p0.s0 State: init PO: 0 B Size: 128 MB S raid5.p0.s1 State: init PO: 512 kB Size: 128 MB S raid5.p0.s2 State: init PO: 1024 kB Size: 128 MB S raid5.p0.s3 State: init PO: 1536 kB Size: 128 MB S raid5.p0.s4 State: init PO: 1536 kB Size: 128 MBThe following figure represents this volume graphically.
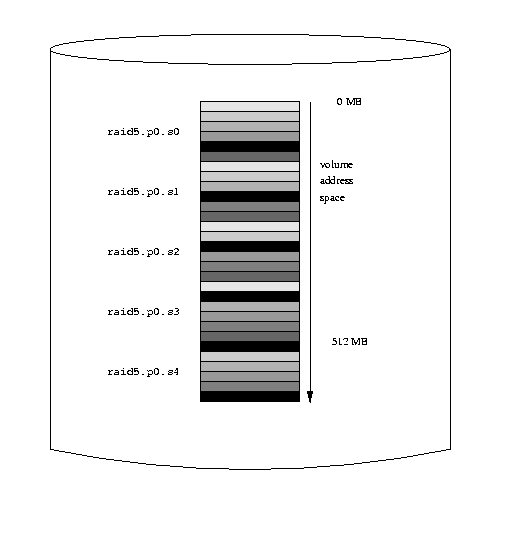
A RAID-5 Vinum volume
As with striped plexes, the darkness of the stripes indicates the position within the plex address space: the lightest stripes come first, the darkest last. The completely black stripes are the parity stripes.
On creation, RAID-5 plexes are in the init state: before they can be used, the parity data must be created. Vinum currently initializes RAID-5 plexes by writing binary zeros to all subdisks, though a conceivable alternative would be to rebuild the parity blocks, which would allow better recovery of crashed plexes.
volume raid10
plex org striped 512k
sd length 102480k drive a
sd length 102480k drive b
sd length 102480k drive c
sd length 102480k drive d
sd length 102480k drive e
plex org striped 512k
sd length 102480k drive c
sd length 102480k drive d
sd length 102480k drive e
sd length 102480k drive a
sd length 102480k drive b
The subdisks of the second plex are offset by two drives from those of the first
plex: this helps ensure that writes do not go to the same subdisks even if a
transfer goes over two drives.
The following figure represents the structure of this volume.
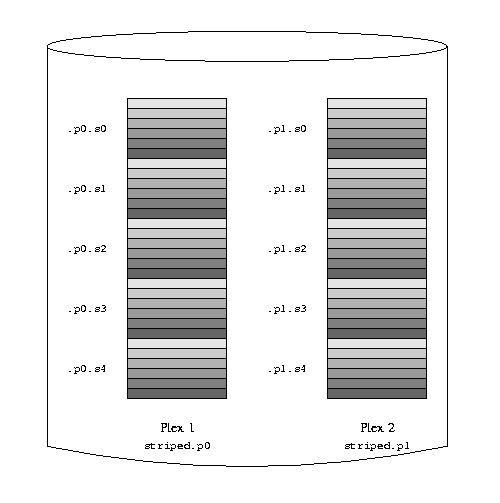
A mirrored, striped Vinum volume
Names may contain any non-blank character, but it is recommended to restrict them to letters, digits and the underscore characters. The names of volumes, plexes and subdisks may be up to 64 characters long, and the names of drives may up to 32 characters long.
Vinum objects are assigned device nodes in the hierarchy /dev/vinum. The configuration shown above would cause Vinum to create the following device nodes:
Although it is recommended that plexes and subdisks should not be allocated specific names, Vinum drives must be named. This makes it possible to move a drive to a different location and still recognize it automatically.
Normally, newfs(8) interprets the name of the disk and complains if it cannot understand it. For example:
# newfs /dev/vinum/concat newfs: /dev/vinum/concat: can't figure out file system partitionIn order to create a file system on this volume, use the -v option to newfs(8):
# newfs -v /dev/vinum/concat
start_vinum=YES